
Iterating Toward Your Ideal Architecture

We were serving our static assets, a React application (with React-router — we will discuss a related gotcha later in the article) with an NGINX container that was being deployed on AWS ECS. Due to some stability issues (likely due to bad NGINX config) and the fact that we wanted to take advantage of the cost savings of S3 hosting, our goal was to move the static assets over to S3 and to be able to access the React site with the same URL as when it was deployed on ECS.
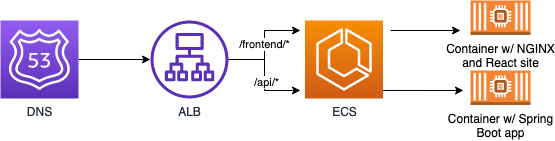
THIS IS THE ARCHITECTURE WE STARTED WITHCustomers access our React site with the URL https://www.our-domain.com/frontend and our API with https://www.our-domain.com/api. This was accomplished by pointing our DNS at an Application Load Balancer. The load balancer would route requests to /frontend/* to a target group at which a container with our React site was deployed. Similarly, the load balancer would route requests to /api/* to a target group at which a container with our Spring Boot application was deployed.
Ideally, we wanted to deploy our React site to S3 with an infrastructure that looks like the following diagram:

OUR IDEAL ARCHITECTUREWe would point our DNS at CloudFront, which would then serve our React site from S3. CloudFront would be configured to forward requests to /api/* to our load balancer. Unfortunately, we could not get CloudFront into place and could not edit DNS records given our time and access constraints. This architecture is still our goal, but we decided to pursue a more short-term solution.
So how can we get traffic through our ALB to S3? One option is to set up a redirect rule in the ALB. If you create a bucket named my-bucket then you can set up the following configuration:

The problem is that this is accomplished by sending a 301 response code to the client, which will then send the client to the bucket’s my-bucket.com.s3-website-us-east-1.amazonaws.com domain. This violates our goal of serving our site through our existing domain name. Rather than using a redirect rule, we can set up a forwarding rule for a target group.

S3, however, cannot be assigned to a target group. As of November of 2018, Lambda functions can be assigned to target groups. So, let’s use a Lamba function to proxy the request from the ALB to S3!
We will be modifying our infrastructure to look like this:

Our target architectureThe official documentation describes the communication contract between the ALB and a Lambda that serves as an ALB target.
Here is an example request:

And an example response:

Ok, this should be simple enough. The idea is that we will use the node.js AWS S3 client in our Lambda function to retrieve items from the bucket associated with the incoming request and then return the contents in our response to the ALB.
We did, however, run into a couple of gotchas while implementing the function.
1. Data Encoding
The ALB expects us to return a JSON payload in response from our Lambda. This is great for any content we want to return to a client that can be expressed as text — html for example. A typical website is composed of both text data (e.g. html, css, js) and binary data (e.g. images, gzipped files). So for any requests for binary content from our S3 bucket, we must make one additional step: Base64 encode the binary data and then set isBase64Encoded to true in our response to the ALB. Before passing the response to the client, the ALB will automatically decode that binary data.

2. React Router
There is a pretty well-known problem to deal with when deploying a React application with react-router to S3. That problem is that requests to routes that are defined by react-router will result in 404 responses because S3 will attempt to serve a nonexistent file from that URL. A lot of web content has been written about how to deal with this problem, such as this Medium article and this thread from Stack Overflow.
The simplest fix is to configure the S3 bucket to return your react app’s index.html as an error document. That way, in the event of a 404, the react app is able to take control and route the request appropriately.

Unfortunately, this doesn’t quite work when using the js S3 client in a lambda function. If we make a request to get an item in the bucket that doesn’t exist, we receive this response:

So, while setting up the S3 bucket configuration doesn’t quite get us the behavior we are looking for, we can do something conceptually identical within our lambda function.

If we fail to retrieve the requested key due to a 404, we will simply request the index.html file. In the end, our function looks something like this:

After deploying our function and configuring our ALB as necessary, we were able to fix the stability issues for our front end that we were facing. There are, however, numerous downsides to this approach.
We have introduced additional latency to each response for a front end resource.
Our site is fairly simple and still has several files that the browser retrieves when a user visits our site. We must send our user the
index.html, 2 Javascript files, a CSS file, and 2 images. That means that our lambda function is invoked 6 times for each visit to the webpage.This is not a cost-effective solution. Sure, we are saving money by hosting our site on S3 vs ECS, but each of those Lambda invocations will add up.
Well, what are the upsides? The first one is that this was a quick-to-implement short-term solution for the stability issues that we were facing. The second is that moving our site to S3 is a good first step in our desired architectural refactor. Now we will work on gaining access to DNS and deploy a CDN so we can get to our ideal architecture as quickly as possible!

our ideal architecture