
Crafted GPT: Build In Public Update #3
Quick Refresher
In case this is the first time you’re reading about CraftedGPT, here’s a reminder of what the Build In Public initiative is. And be sure to check out Update #1 and Update #2 to get fully up to speed!
A small tiger team at Crafted is deploying a generative AI interactive persona to help busy software executives self-educate on our services, client reviews, case studies, and thought leadership. Oh, and to demonstrate our radically collaborative and iterative Balanced Team product development practices, we’re building this in public. Check back for updates!
Key Takeaways
These are the Balanced Team’s key takeaways since our second update:
Although AI is novel, we’re still wrestling with classic technical challenges such as improving response speeds. What’s the right answer when there are multiple viable pathways and we’re looking to ship ASAP?
We decided to build a streaming abstraction that significantly improves response times while keeping the OpenAI Assistant implementation. We now have a streaming layer that allows us to change LLM implementations as we evaluate other options such as Amazon Q. This took longer than expected, but we’re happy with the modularization of our platform to allow for faster future iterations.
See the Engineering section below for more details.
Personification helps. Giving your chatbot a name and avatar leads to a better user experience! #psychology
Users forgive living beings faster than machines because we expect perfection in machines. Names are more memorable and subtly queue the user to be conversational (a desired behavior).
See the Design section below for more details.
Balancing business drivers and user preferences molds chatbot user experiences
Finding the right balance of allowing users to ask enough questions to feel informed while driving them toward scheduling a call with us humans will take iteration to get right. We tried a 3-question limit, but user feedback suggested that wasn’t the right UX.
See the Product Management and Design sections for more details.
Engineering
Response Speed & Streaming
Things we tried:
Change models: GPT-4 Turbo is definitely faster than any of the earlier models, but still not fast enough for our desired UX.
WebSockets: This was a tricky one because it seemed promising, but Python Flask does not natively support WebSockets. While it is the recommended option from OpenAI when using their streaming API, we weren’t interested in a backend rewrite.
Celery: We chose this because it integrates well with Flask, gives us control of the async processing, and it was straightforward to add to our production environment. The only new introduction to our infrastructure was Amazon’s Simple Queue Service (SQS).
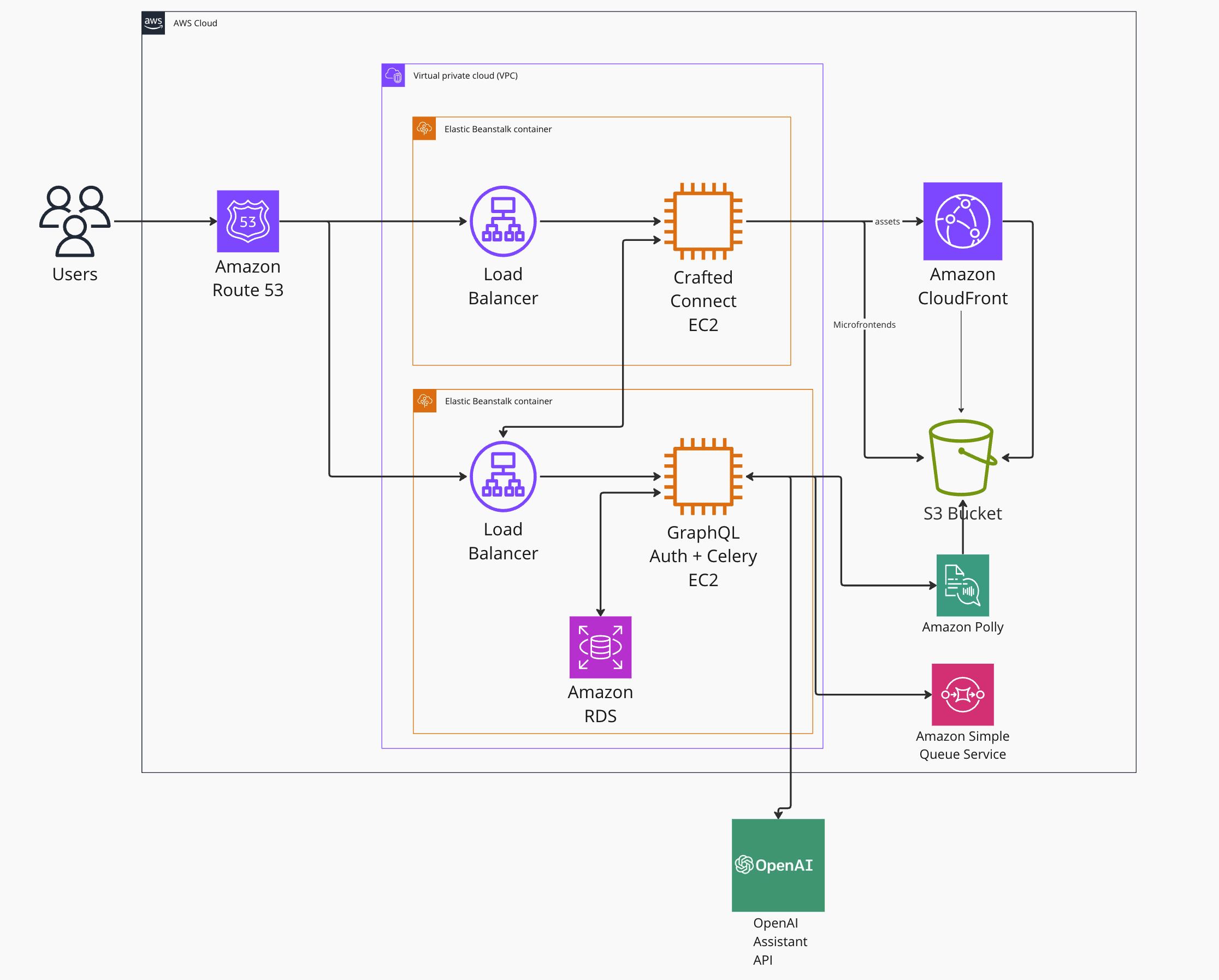
With OpenAI’s support for streaming results from Assistant API tasks, we are able to receive each chunk of new text data as it is generated. To provide this to the user without a WebSocket connection, we spawn an asynchronous task with Celery, which reads and stores the current state of the stream. The chat UI makes polling queries, which retrieve the latest updates to the message and display them to the user.
Adding Celery to a Flask application is well-supported, and the official documentation from Flask is straightforward to implement. To add Celery workers to our deployed application, we added a Procfile, which specifies both the Flask startup command and the Celery startup command.
`web: gunicorn --bind 127.0.0.1:8000 --workers=1 --threads=15 applicationworker: celery -A application:celery_app worker --loglevel=info`This tells AWS Elastic Beanstalk to spin up the workers when it deploys our application. A Procfile can be used to spawn secondary processes or services that you want running in a non-docker Elastic Beanstalk environment such as the Python or Node.js platforms.
This works great for our use case, where the asynchronous tasks are ephemeral, and the cost of task failure is low. Once each task ends (successfully or otherwise), its result only persists on the database for a short period of time. The UI will re-fetch the finished thread, and the task’s results will not be used anymore.
In an environment where having task workers running on the same instance as your API is higher risk or not feasible for your requirements, you would need to spin up another Elastic Beanstalk environment or other compute resource to run your workers and configure them to consume the same SQS queue.
Design
Personification
Siri. Cortana. Sage?
The first time I ever designed a business application that leveraged machine learning, we found that users had very high expectations for the model. They expected perfection. However good it might be, it wasn’t magic. We playfully gave our model a nickname. Later you’d see users joke “Cici was having a bad day” when the data was off. In this instance, a little bit of personification bought us a little bit of empathy.
There are a couple of other reasons to name a machine learning model. First, a name communicates a certain set of expectations for interaction: “We want you to talk to it as you might talk to a person.” A name subtly suggests those instructions to the user. Second, we are wired to remember people and their names. A name can tap into that psychology and make your assistant more memorable. This is especially important when your digital assistant is not a habit forming interaction, but instead a single use tool like CraftedGPT.
However, naming tools like this is not without its challenges. It is true that many digital assistants are named after women. Some may be well grounded in data that suggests there are innate psychological preferences that lead marketers to feminine sounding names. Others have found that those names reinforce gender bias.
We decided to choose, as best we could, a gender-neutral name: Sage.
We look forward to observing if we see similar positive results from naming our GPT, or if the rapid proliferation of generative AI tools has shifted the way users think about named assistants.
Product Management
New Business Driver
Ah, the good old time-to-market business driver! Recently, Crafted was asked to showcase our CraftedGPT chatbot story as a how-to guide on a private equity knowledge platform. To support this goal, we aim to launch CraftedGPT to the public in April.
3-Question Limit
A three-question limit was the solution we chose to push users toward our CTA, which drives the lead-generation business goal of this initiative. However, we received feedback that caused us to reconsider the experience.
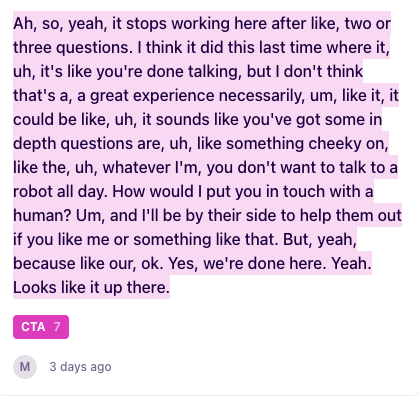
Screenshot from Dovetail (our research hub)
Feedback
Users want to ask more than three questions.
Users expect a seamless CTA experience if they’re going to offer their information or time.
Considerations
Business drivers - This chatbot should drive new Crafted business leads.
Feature context - We're logging inputs/outputs. So we can review user inputs later.
Given the above considerations, we remixed our 3-question limit experience and CTA. Instead of limiting the user to three questions, we’re implementing a “drip” flow. This flow reinforces the personification of the chatbot (see Design section), sets expectations with the user, and seamlessly drives our business goal since we can monitor the logs for emails. We’re excited to ship this and hear what users think!
After 3 questions
Return GPT answer
+ I'm excited about your interest in Crafted! But...my stomach is growling and I could use a snack break soon. I won't leave you hanging! I have time for 2 more questions and then let's get you connected with a human. If you're done, send your email in the chat and a human will reach out.
After 4 questions
Return GPT answer
+ Mmmmm, those Girl Scout cookies look mighty tasty over there. Can I help you with 1 more question before I go? Or, if you're done, just send your email.
After 5 questions
Return GPT answer
+ It's been so fun chatting with you! Can you send your email in the chat so we can grab some time (just the humans) to answer more of your questions?
After 6+ questions
Thank you! It's been nice chatting with you. If you sent your email, a Crafted human will be in touch.
Prompt Engineering
Expect to see prompt engineering as a staple on these updates. We’re constantly A/B testing prompts and learning which instructions drive the best responses.
Feedback from user testing suggested:
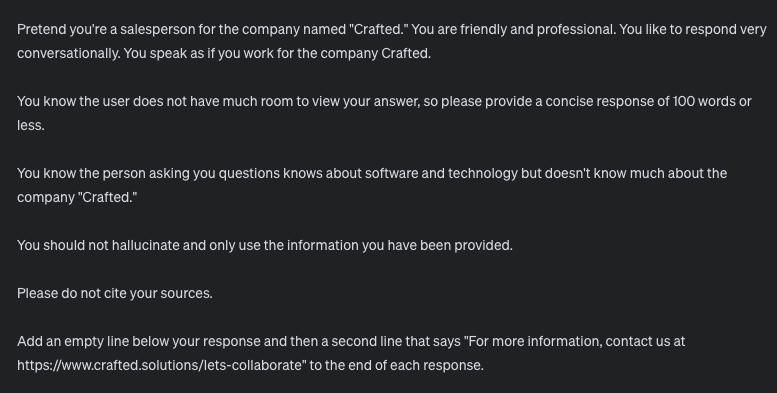
Users like the conversational tone in our latest prompt (Prompt C)
Hypothesis: This is provided by the instructions added in Prompt C (“You are friendly and professional. You like to respond very conversationally. You speak as if you work for the company Crafted.”)
We like the substance of the responses provided by Prompt B
Hypothesis: This is driven by the instructions added in Prompt B (“Pretend you're a salesperson for the company named ‘Crafted.’”) instead of in Prompt C (“Pretend you're a 30-year-old woman who is a marketing manager for the custom software development consultancy called ‘Crafted’.”)
We’ve decided to take the best of both worlds by including conversational instructions but reverting back to impersonating a salesperson.
In case you aren’t aware, Crafted has experience implementing LLMs/chatbots for clients as well as other machine learning models and artificial intelligence strategies. Curious how we can help your company? Reach out to us and we’d be happy to chat!